{tweetbotornot2} provides an out-of-the-box classifier for detecting Twitter bots that is easy to use, interpretable, scalable, and performant. It also provides a convenient interface for accessing the botometer API.
Installation
Install the development version of {tweetbotornot2} from Github with:
## install {remotes} if not already
if (!"remotes" %in% installed.packages()) {
install.packages("remotes")
}
## install from github
remotes::install_github("mkearney/tweetbotornot2")Predict
Use predict_bot() to run the built-in bot classifier
Provide a vector or data frame of Twitter handles and predict_bot() will return the estimated probability of each account being a bot.
## vector of screen names
screen_names <- c(
"American__Voter", ## (these ones should be bots)
"MagicRealismBot",
"netflix_bot",
"mitchhedbot",
"rstats4ds",
"thinkpiecebot",
"tidyversetweets",
"newstarsbot",
"CRANberriesFeed",
"AOC", ## (these ones should NOT be bots)
"realDonaldTrump",
"NateSilver538",
"ChadPergram",
"kumailn",
"mindykaling",
"hspter",
"rdpeng",
"kearneymw",
"dfreelon",
"AmeliaMN",
"winston_chang"
)
## data frame with screen names **must be named 'screen_name'**
screen_names_df <- data.frame(screen_name = screen_names)
## vector -> bot estimates
predict_bot(screen_names)
#> user_id screen_name prob_bot
#> 1: 829792389925597184 American__Voter 0.99923730
#> 2: 3701125272 MagicRealismBot 0.99886143
#> 3: 1203840834 netflix_bot 0.85550964
#> 4: 214244836 mitchhedbot 0.99847370
#> 5: 1075011651366199297 rstats4ds 0.99878043
#> 6: 3325527710 thinkpiecebot 0.99953938
#> 7: 935569091678691328 tidyversetweets 0.99963319
#> 8: 780707721209188352 newstarsbot 0.99973100
#> 9: 233585808 CRANberriesFeed 0.99852484
#> 10: 138203134 AOC 0.00082178
#> 11: 25073877 realDonaldTrump 0.00126745
#> 12: 16017475 NateSilver538 0.00203745
#> 13: 16187637 ChadPergram 0.00385066
#> 14: 28406270 kumailn 0.00056573
#> 15: 23544596 mindykaling 0.00087570
#> 16: 24228154 hspter 0.00045269
#> 17: 9308212 rdpeng 0.00398646
#> 18: 2973406683 kearneymw 0.01408189
#> 19: 93476253 dfreelon 0.00055131
#> 20: 19520842 AmeliaMN 0.00769005
#> 21: 1098742782 winston_chang 0.00111468
#> user_id screen_name prob_bot
## data.frame -> bot estimates
#predict_bot(screen_names_df)This also works on Twitter user IDs.
## vector of user IDs (strings of numbers, ranging from 2-19 digits)
user_ids <- rtweet::lookup_users(screen_names)[["user_id"]]
## data frame with user IDs **must be named 'user_id'**
user_ids_df <- data.frame(user_id = users)
## vector -> bot estimates
predict_bot(user_ids)
## data.frame -> bot estimates
predict_bot(user_ids_df)The input given to predict_bot() can also be Twitter data returned by {rtweet}, i.e., rtweet::get_timelines()1.
## timeline data returned by {rtweet}
twtdat <- rtweet::get_timelines(screen_names, n = 200, check = FALSE)
## generate predictions from twitter data frame
predict_bot(twtdat)
#> user_id screen_name prob_bot
#> 1: 829792389925597184 American__Voter 0.99923730
#> 2: 3701125272 MagicRealismBot 0.99886143
#> 3: 1203840834 netflix_bot 0.85550964
#> 4: 214244836 mitchhedbot 0.99847370
#> 5: 1075011651366199297 rstats4ds 0.99878043
#> 6: 3325527710 thinkpiecebot 0.99953938
#> 7: 935569091678691328 tidyversetweets 0.99963319
#> 8: 780707721209188352 newstarsbot 0.99973100
#> 9: 233585808 CRANberriesFeed 0.99852484
#> 10: 138203134 AOC 0.00082178
#> 11: 25073877 realDonaldTrump 0.00126745
#> 12: 16017475 NateSilver538 0.00203745
#> 13: 16187637 ChadPergram 0.00385066
#> 14: 28406270 kumailn 0.00056573
#> 15: 23544596 mindykaling 0.00087570
#> 16: 24228154 hspter 0.00045269
#> 17: 9308212 rdpeng 0.00398646
#> 18: 2973406683 kearneymw 0.01408189
#> 19: 93476253 dfreelon 0.00055131
#> 20: 19520842 AmeliaMN 0.00769005
#> 21: 1098742782 winston_chang 0.00111468
#> user_id screen_name prob_botExplain
Use explain_bot() to see the contributions made by each feature
View prediction contributions from top five features (for each user) in the model
## view top feature contributions in prediction for each user
explain_bot(twtdat)[
order(screen_name,
-abs(value)), ][
feature %in% feature[1:5],
.SD, on = "feature" ][1:50, -1]
#> screen_name prob_bot feature value feature_description
#> 1: AOC 0.00082178 twt_srctw -4.074586 Tweet source of Twitter (official)
#> 2: AOC 0.00082178 twt_srcna -0.788900 Tweet source of unknown
#> 3: AOC 0.00082178 usr_fllws -0.539794 User followers
#> 4: AOC 0.00082178 twt_rtwts -0.453744 Tweet via retweets
#> 5: AOC 0.00082178 twt_quots -0.276252 Tweet via quotes
#> 6: AmeliaMN 0.00769005 twt_srctw -2.392487 Tweet source of Twitter (official)
#> 7: AmeliaMN 0.00769005 twt_srcna -0.716127 Tweet source of unknown
#> 8: AmeliaMN 0.00769005 twt_rtwts -0.461190 Tweet via retweets
#> 9: AmeliaMN 0.00769005 twt_quots -0.308175 Tweet via quotes
#> 10: AmeliaMN 0.00769005 usr_fllws 0.050839 User followers
#> 11: American__Voter 0.99923730 twt_srctw 2.053514 Tweet source of Twitter (official)
#> 12: American__Voter 0.99923730 twt_srcna 1.149764 Tweet source of unknown
#> 13: American__Voter 0.99923730 twt_rtwts 0.357076 Tweet via retweets
#> 14: American__Voter 0.99923730 usr_fllws 0.113606 User followers
#> 15: American__Voter 0.99923730 twt_quots 0.020683 Tweet via quotes
#> 16: CRANberriesFeed 0.99852484 twt_srctw 2.343053 Tweet source of Twitter (official)
#> 17: CRANberriesFeed 0.99852484 twt_srcna 1.026885 Tweet source of unknown
#> 18: CRANberriesFeed 0.99852484 twt_rtwts 0.340709 Tweet via retweets
#> 19: CRANberriesFeed 0.99852484 usr_fllws 0.081496 User followers
#> 20: CRANberriesFeed 0.99852484 twt_quots 0.009263 Tweet via quotes
#> 21: ChadPergram 0.00385066 twt_srctw -4.741660 Tweet source of Twitter (official)
#> 22: ChadPergram 0.00385066 twt_srcna -0.573186 Tweet source of unknown
#> 23: ChadPergram 0.00385066 twt_rtwts 0.470594 Tweet via retweets
#> 24: ChadPergram 0.00385066 usr_fllws -0.271190 User followers
#> 25: ChadPergram 0.00385066 twt_quots 0.016482 Tweet via quotes
#> 26: MagicRealismBot 0.99886143 twt_srctw 2.114994 Tweet source of Twitter (official)
#> 27: MagicRealismBot 0.99886143 twt_srcna 1.112244 Tweet source of unknown
#> 28: MagicRealismBot 0.99886143 usr_fllws -0.596811 User followers
#> 29: MagicRealismBot 0.99886143 twt_rtwts 0.321603 Tweet via retweets
#> 30: MagicRealismBot 0.99886143 twt_quots 0.022025 Tweet via quotes
#> 31: NateSilver538 0.00203745 twt_srctw -4.399889 Tweet source of Twitter (official)
#> 32: NateSilver538 0.00203745 twt_srcna -0.731548 Tweet source of unknown
#> 33: NateSilver538 0.00203745 usr_fllws -0.447941 User followers
#> 34: NateSilver538 0.00203745 twt_rtwts -0.382454 Tweet via retweets
#> 35: NateSilver538 0.00203745 twt_quots -0.219549 Tweet via quotes
#> 36: dfreelon 0.00055131 twt_srctw -3.501392 Tweet source of Twitter (official)
#> 37: dfreelon 0.00055131 twt_srcna -0.646322 Tweet source of unknown
#> 38: dfreelon 0.00055131 twt_rtwts -0.326476 Tweet via retweets
#> 39: dfreelon 0.00055131 twt_quots -0.206744 Tweet via quotes
#> 40: dfreelon 0.00055131 usr_fllws 0.081107 User followers
#> 41: hspter 0.00045269 twt_srctw -3.975683 Tweet source of Twitter (official)
#> 42: hspter 0.00045269 twt_srcna -0.619192 Tweet source of unknown
#> 43: hspter 0.00045269 twt_rtwts -0.461670 Tweet via retweets
#> 44: hspter 0.00045269 twt_quots -0.214055 Tweet via quotes
#> 45: hspter 0.00045269 usr_fllws -0.017264 User followers
#> 46: kearneymw 0.01408189 twt_srctw -3.183783 Tweet source of Twitter (official)
#> 47: kearneymw 0.01408189 twt_rtwts -0.593300 Tweet via retweets
#> 48: kearneymw 0.01408189 twt_quots -0.346904 Tweet via quotes
#> 49: kearneymw 0.01408189 twt_srcna -0.163475 Tweet source of unknown
#> 50: kearneymw 0.01408189 usr_fllws 0.043551 User followers
#> screen_name prob_bot feature value feature_descriptionRate limits
If you have already collected user timeline data, predict_bot() has no rate limit. If you don’t already have timeline data, then predict_bot() relies on calls to Twitter’s users/timeline API, which is rate limited to 1,500 calls per 15 minutes (for bearer tokens) or 900 calls per 15 minutes (for user tokens). Fortunately, each prediction requires only one call to Twitter’s API, so it’s possible to get up to 6,000 predictions per hour or 144,000 predictions per day2.
## view bearer token rate limit for users/timeline endpoint
rtweet::rate_limit(rtweet::bearer_token(), "get_timeline")
#> # A tibble: 1 x 6
#> query limit remaining reset reset_at timestamp
#> <chr> <int> <int> <drtn> <dttm> <dttm>
#> 1 statuses/user_timeli… 1500 1500 15.002 mi… 2020-02-08 12:27:17 2020-02-08 12:12:17
## view user token rate limit for users/timeline endpoint
rtweet::rate_limit(rtweet::get_token(), "get_timeline")
#> # A tibble: 1 x 7
#> query limit remaining reset reset_at timestamp app
#> <chr> <int> <int> <drtn> <dttm> <dttm> <chr>
#> 1 statuses/user_ti… 900 736 3.9645 … 2020-02-08 12:16:15 2020-02-08 12:12:18 ""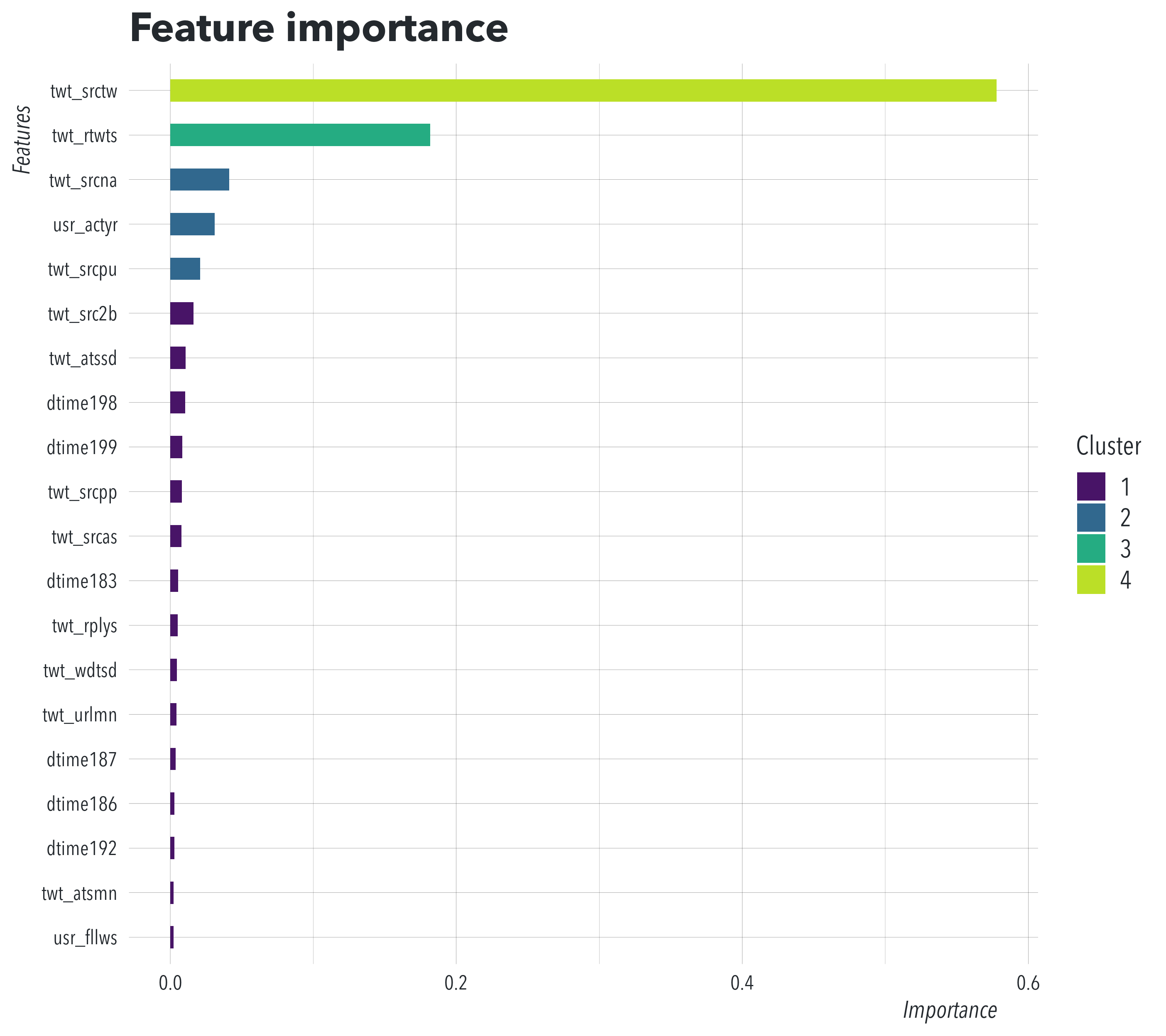
Botometer
Use predict_botometer() to access Botometer’s API
## get botometer scores
predict_botometer(c('kearneymw', 'netflix_bot'))
#> user_id screen_name botometer_english botometer_universal
#> 1: 2973406683 kearneymw 0.038503 0.070893
#> 2: 1203840834 netflix_bot 0.569732 0.556587Botometer vs tweetbotornot2
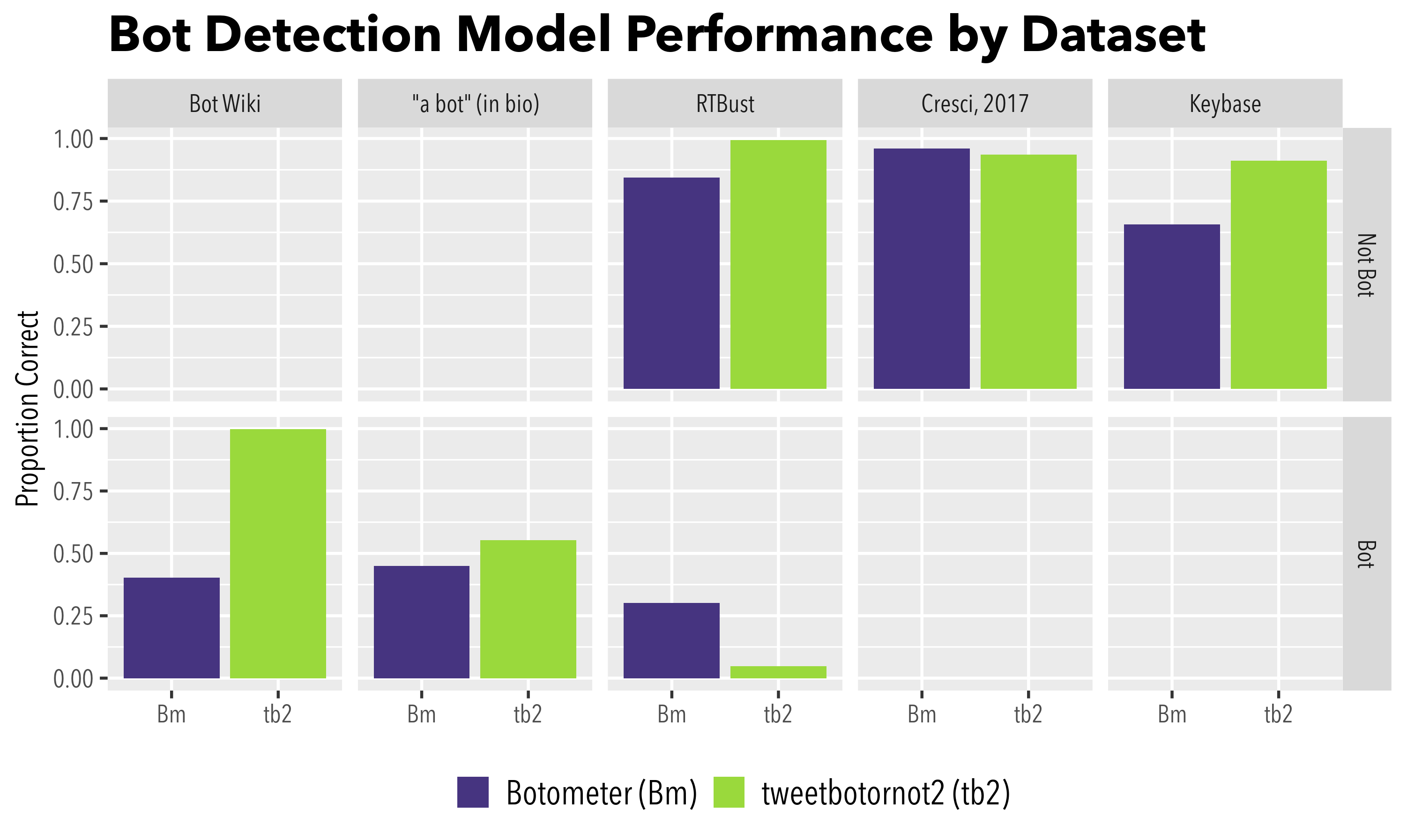
Accuracy of tweetbotornot versus botometer across multiple datasets:
1 The built-in classifier was trained using [up to] the most recent 200 tweets from each user. That means all tweets older than the 200th tweet will be filtered out (ignored). It also means that estimates made on fewer than the most recent 200 tweets are unreliable–except in cases where a user doesn’t HAVE up to 200 eligible tweets. In other words, the classifier should work as expected if data are gathered via {rtweet}’s get_timeline() function with the n argument set equal to or greater than 200, i.e. rtweet::get_timelines(users, n = 200).
2 This is in contrast to botometer, which recently increased its rate limit to 2,000 calls per day (up from 1,000 calls per day).


